Django Upload Csv File Check for Duplicate
Python is one of the most popular programming languages for information analysis and besides supports various Python data-axial packages. The Pandas packages are some of the most popular Python packages and tin can exist imported for data analysis. In almost all datasets, duplicate rows often exist, which may cause problems during data analysis or arithmetic operation. The best approach for data assay is to identify any duplicated rows and remove them from your dataset. Using the Pandas drop_duplicates() function, you lot can hands driblet, or remove, duplicate records from a information frame.
This article shows you how to find duplicates in data and remove the duplicates using the Pandas Python functions.
In this article, we have taken a dataset of the population of different states in the Us, which is available in a .csv file format. We will read the .csv file to show the original content of this file, as follows:
import pandas as pd
df_state=pd.read_csv ( "C:/Users/DELL/Desktop/population_ds.csv" )
print (df_state)
In the following screenshot, you lot can see the duplicate content of this file:
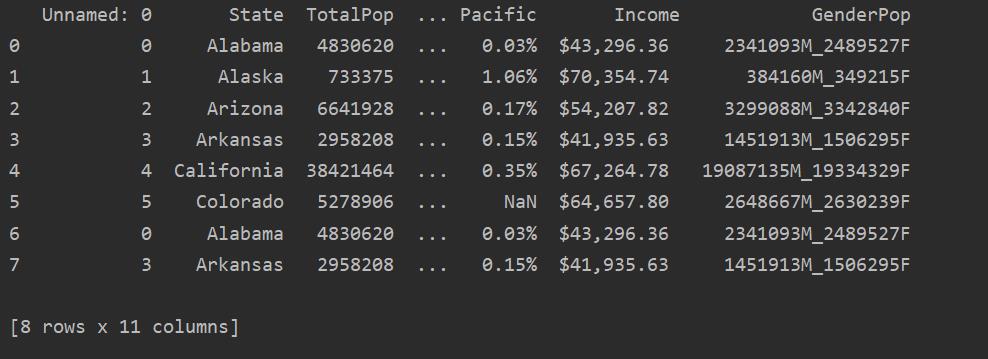
Identifying Duplicates in Pandas Python
It is necessary to determine whether the data you lot are using has duplicated rows. To cheque for information duplication, you can use whatever of the methods covered in the following sections.
Method 1:
Read the csv file and pass it into the data frame. Then, identify the duplicate rows using the duplicated() function. Finally, employ the impress statement to brandish the duplicate rows.
import pandas as pd
df_state=pd.read_csv ( "C:/Users/DELL/Desktop/population_ds.csv" )
Dup_Rows = df_state[df_state.duplicated ( ) ]
impress ( "\n \nDuplicate Rows : \n {}".format (Dup_Rows) )

Method 2:
Using this method, the is_duplicated cavalcade volition be added to the end of the tabular array and marked equally 'True' in the case of duplicated rows.
import pandas every bit pd
df_state=pd.read_csv ( "C:/Users/DELL/Desktop/population_ds.csv" )
df_state[ "is_duplicate" ] = df_state.duplicated ( )
print ( "\north {}".format (df_state) )
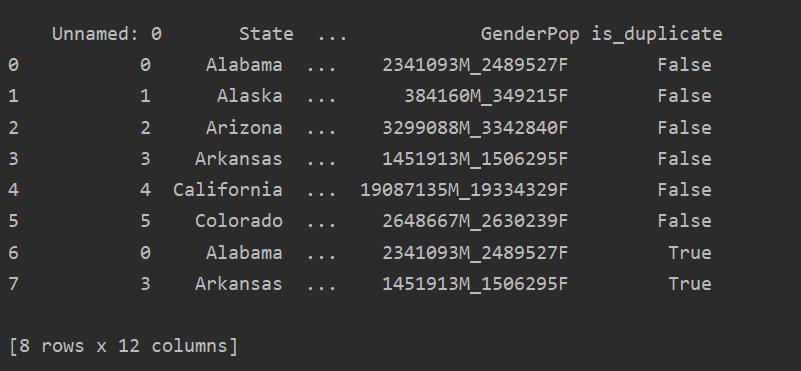
Dropping Duplicates in Pandas Python
Duplicated rows can be removed from your data frame using the following syntax:
drop_duplicates(subset='', continue='', inplace=False)
The above iii parameters are optional and are explained in greater detail below:
continue: this parameter has three different values: First, Last and Fake. The First value keeps the first occurrence and removes subsequent duplicates, the Terminal value keeps simply the last occurrence and removes all previous duplicates, and the False value removes all duplicated rows.
subset: characterization used to identify the duplicated rows
inplace: contains two weather: True and Fake. This parameter will remove duplicated rows if it is set to Truthful.
Remove Duplicates Keeping Only the First Occurrence
When you use "keep=first," just the first row occurrence will exist kept, and all other duplicates volition be removed.
Instance
In this example, simply the offset row will be kept, and the remaining duplicates will be deleted:
import pandas every bit pd
df_state=pd.read_csv ( "C:/Users/DELL/Desktop/population_ds.csv" )
Dup_Rows = df_state[df_state.duplicated ( ) ]
print ( "\n \nDuplicate Rows : \north {}".format (Dup_Rows) )
DF_RM_DUP = df_state.drop_duplicates (go on= 'start' )
impress ( '\northward \northResult DataFrame after duplicate removal :\n' , DF_RM_DUP.head (n= v ) )
In the following screenshot, the retained first row occurrence is highlighted in red and the remaining duplications are removed:
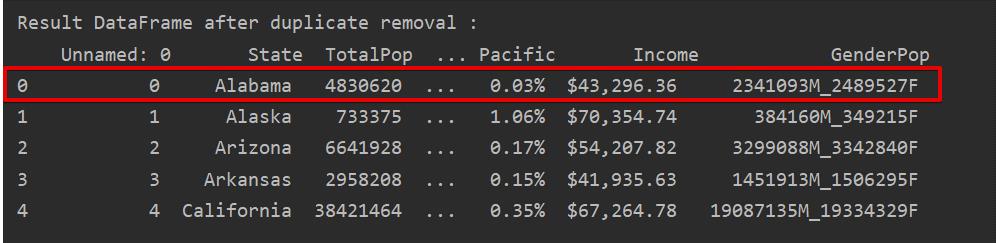
Remove Duplicates Keeping Only the Final Occurrence
When you utilise "go along=terminal," all duplicate rows except the last occurrence volition exist removed.
Example
In the following example, all duplicated rows are removed except only the last occurrence.
import pandas as pd
df_state=pd.read_csv ( "C:/Users/DELL/Desktop/population_ds.csv" )
Dup_Rows = df_state[df_state.duplicated ( ) ]
print ( "\n \due northDuplicate Rows : \north {}".format (Dup_Rows) )
DF_RM_DUP = df_state.drop_duplicates (continue= 'final' )
print ( '\north \northResult DataFrame after duplicate removal :\due north' , DF_RM_DUP.caput (n= 5 ) )
In the following epitome, the duplicates are removed and merely the last row occurrence is kept:

Remove All Duplicate Rows
To remove all duplicate rows from a table, gear up "go on=Fake," as follows:
import pandas as pd
df_state=pd.read_csv ( "C:/Users/DELL/Desktop/population_ds.csv" )
Dup_Rows = df_state[df_state.duplicated ( ) ]
print ( "\n \northDuplicate Rows : \n {}".format (Dup_Rows) )
DF_RM_DUP = df_state.drop_duplicates (keep= Imitation )
impress ( '\n \northIssue DataFrame after indistinguishable removal :\north' , DF_RM_DUP.head (n= v ) )
Equally you can run into in the following image, all duplicates are removed from the data frame:

Remove Related Duplicates from a Specified Column
By default, the function checks for all duplicated rows from all the columns in the given data frame. But, y'all can also specify the column name by using the subset parameter.
Example
In the following instance, all related duplicates are removed from the 'States' column.
import pandas as pd
df_state=pd.read_csv ( "C:/Users/DELL/Desktop/population_ds.csv" )
Dup_Rows = df_state[df_state.duplicated ( ) ]
impress ( "\northward \nDuplicate Rows : \n {}".format (Dup_Rows) )
DF_RM_DUP = df_state.drop_duplicates (subset= 'Country' )
print ( '\n \nResult DataFrame after duplicate removal :\n' , DF_RM_DUP.head (n= six ) )

Conclusion
This article showed yous how to remove duplicated rows from a data frame using the drop_duplicates() function in Pandas Python. Y'all tin can also articulate your information of duplication or back-up using this role. The article likewise showed you how to identify any duplicates in your information frame.
About the author
Samreena Aslam holds a master'south degree in Software Technology. Currently, she's working as a Freelancer & Technical author. She'south a Linux enthusiast and has written various articles on Computer programming, different Linux flavors including Ubuntu, Debian, CentOS, and Mint.
Source: https://linuxhint.com/drop-duplicates-pandas-python/
0 Response to "Django Upload Csv File Check for Duplicate"
Post a Comment